1.varchar(1) 只能存一個字
2.效能 char>nchar>varchar>nvarchar 因var因為額外儲存地址,讀取時會先去抓資料,會比非var來的略慢
3.n是指支援unicode,一字存 2Byte
4.char varchar差在char固定長度varchar會自動延伸
char(4 byte varchar 4個字
4.desc table_name 可以看欄位資料

5.nchar相等char(x) character set utf8=national character(1)
CHAR(10) CHARACTER SET utf8 NATIONAL CHARACTER(10) NCHAR(10)
6.
character set 字符集:選你的語言要挑的 如:big5中文utf8mb
collation排序規則:

7. 在跨庫多表連接查詢時,若兩資料庫默認字元集不同,系統就會返回這樣的錯誤:
create table #t1(
name varchar(20) collate Albanian_CI_AI_WS,
value int)
create table #t2(
name varchar(20) collate Chinese_PRC_CI_AI_WS,
value int )
表建好後,執行連接查詢:
select * from #t 1 A inner join #t2 B on A.name=B.name
這樣,錯誤就出現了:
要排除這個錯誤,最簡單方法是,表連接時指定它的排序規則,這樣錯誤就
不再出現了。語句這樣寫:
select *
from #t 1 A inner join #t2 B
on A.name=B.name collate Chinese_PRC_CI_AI_WS
來源:http://blog.xuite.net/hsiung03/blog/63620934-SQL+Server+%E4%B8%ADcollate%E7%9A%84%E5%90%AB%E7%BE%A9
8.show collation,show character set
9.
char(n):n Byte
varchar(n):(n + 2) Byte --2Byte記錄地址
nchar(n):(2 * n) Byte
nvarchar(n):(2 * n + 2) Byte
https://dotblogs.com.tw/henryli/archive/2014/05/27/145277.aspx
10.unsigned的意義
int 可以裝到32767
unsigned會把負數加上去變0~65535
|
有 |
16bit |
int(short) |
-32768->32767 |
|
32 |
long |
-2147483648->2147483647 |
|
|
無 |
16 |
unsigned int |
0->65535 |
11.tinyint 1byte -128~127
tinyint(100) 這個100指length
但要zerofill
ex:alter table table_name modify a_column tinyint(10) zerofill
在mysql query
會補0
「ZEROFILL」一定要跟「UNSIGNED」一起使用,就算你只有為欄位設定「ZEROFILL」,MySQL也會自動加入「UNSIGNED」的設定。


http://www.codedata.com.tw/database/mysql-tutorial-8-storage-engine-datatype/
12.

13. 在 UTF-8 的編碼,一個中文 3 bytes
big5 一個中文算 2 byte, 不同的編碼,中文的長度不同
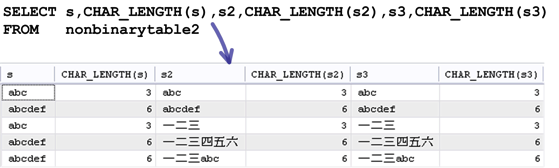
14.length方法和char_length
length傳回byte長度
char_length傳回實際字數

「LENGTH」函式會傳回字串資料實際的儲存長度(byte);如果你要查詢字串的字元數量的話,就要使用「CHAR_LENGTH」函式:
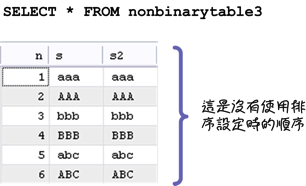
字元集會影響字串的儲存空間,collation會影響字串排列順序。以下列的「cmdev.nonbinarytable3」表格來說:
| 欄位名稱 | 型態 | 字元集 | Collation |
| s | VARCHAR(6) | latin1 | latin1_general_ci |
| s2 | VARCHAR(6) | latin1 | latin1_general_cs |
上列表格中欄位的字元集都指定為「latin1」,不過「s」欄位的collation設定為「latin1_general_ci」,表示排序時不區分大小寫;「s2」欄位設定為「latin1_general_cs」,表示排序時會區分大小寫。以下列儲存在這個表格中紀錄來說:
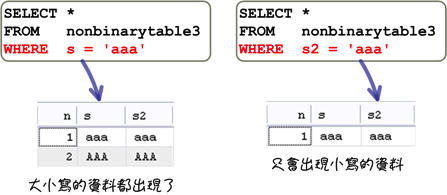
Collation設定中的「latin1_general_ci」,最後的「ci」表示「case insensitive」,是不分大小寫的意思。在這樣的設定下,MySQL會把字串「ABC」和「abc」當成是一樣的;「latin1_general_cs」,最後的「cs」表示「case sensitive」,是區分大小寫的意思。在這樣的設定下,MySQL就會把字串「ABC」和「abc」當成是不一樣的字串。
是否區分大小寫的collation設定會影響排序的結果:

另外一個影響是條件的判斷:
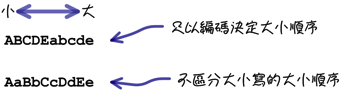
15.列舉
優點:假如以衣服尺寸設計enum,那麼order by 時不會以abcd,而以xs ,s ,m,l,xl排序
可以用where enumsize=1 或者'xs'
正確性:跟varchar相比,因為varchar可以亂輸入,而enum只能輸入xs ,s那幾個,所以正確性較強
列舉(enumeration)的資料在資料庫中的應用很常見,例如服裝的大小就會以S、M與L來表示小、中與大。你可以使用字串來儲存這類資料,不過這類的資料也很適合使用「ENUM」型態來儲存。以下列的「cmdev.enumtable」表格來說:

在儲存資料的時候,「ENUM」型態看起來似乎與「VARCHAR」完全一樣:

可是列舉型態在資料的正確性方面,就會比單純的字串型態好多了。例如下列錯誤示範:

列舉型態欄位除了可以直接使用字串值來新增與更新資料外,還可以使用數值資料的編號來代替,任何一個列舉型態中的成員,MySQL都會幫它們編一個號碼:
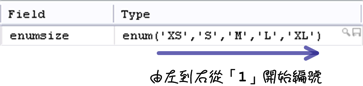
瞭解列舉型態中成員的編號以後,你可以選擇字串值或數值來管理列舉型態欄位儲存的資料:

雖然在查詢列舉型態欄位資料的時候,所得到的結果都是成員的字串值;不過真正儲存在資料庫中的資料卻是成員的編號,所以指定列舉型態欄位為排序欄位的時候,資料庫會使用編號來排序,而不是以成員的字串值:
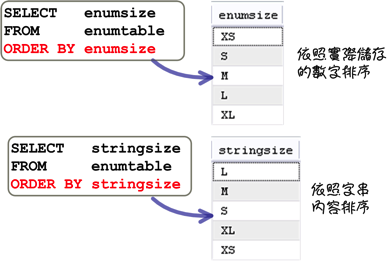
在指定列舉型態欄位的查詢條件時,可以使用成員的字串值或編號:

http://www.codedata.com.tw/database/mysql-tutorial-8-storage-engine-datatype/
16.utf8_general_ci vs utf8_general_cs
ci= case insensitive 不敏感
cs = case sensitive 大小寫敏感
alter table a modify id int(5) charset utf8 collate utf8_general_ci
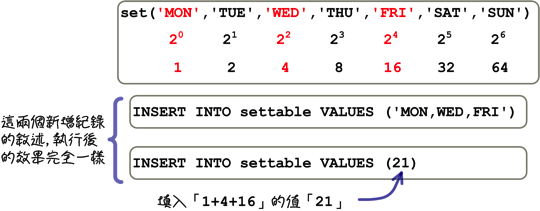
17.set型態
欄位資料可以存成('mon','tues','wed') 禮拜幾的型式
alter table a modify c set('mon','tues','wed')
如要存 工作的星期

具有檢查的功能
也可以用數字

 留言列表
留言列表

